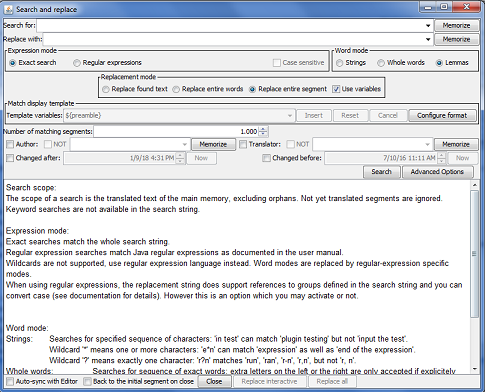
Search and replace
Like the previous screens, the Search and Replace screen also includes a result pane: users should read carefully what the replacement engine will do before validating it via «Replace all».
 |
After the expression/word modes, you can also select how to replace the text :
|
The checkbox « Use variables » makes it possible to use $0, $1, $2 and so on in the replacement string.
- In regular expression search mode, it has the same meaning as in other tools : $0 means the full string, $1 the first group, and so on.
- In exact expression + strings mode, $0 means the full string, $1, $2, $3... means each part with space (including tab, non-break space, etc.) as separator. For example if you search "a*, b" and found "aaa, b" then $1 = "aaa," and $2 = "b"
- In exact expression + whole words mode, $0 means the full string, $1, $2, $3... means words (it totally ignores spaces). For example if you searched for "t?st, essai" and found "test essai", then $1 = test and $2 = essai
Word is defined as any sequence of "letters", in the Unicode meaning (\p{L}) : this is probably difficult to use for languages which do not use spaces. - In exact expression + lemmas mode, $0 means what has been recognized (sequence of letters), $1, $2, $3... means the words which have been found in the string (for example if you search for "all test" and we found "all the tests", then $1 = all, $2 = the (in matching mode, stopwords do not prevent to accept the string!) and $3 = tests)
If you do not check it, $ is simply considered as a normal character, which may be what you prefer. When search for variables is selected, if you want to have the sign '$' in the string, you need to protect it with a \ before.
NEW (DGT-OmegaT 3.0 update 8): replacement with variables now supports also case replacements, meaning the possibility to convert some characters in lower or upercase during replacement. Syntax is the following, inspired by this, with Perl's syntax (meaning that \l\U is valid while \L\u is not), in all modes:
- \u will convert to upercase the next character of the replaced string. For example if $1 = test then \u$1 = Test
- \l will convert to lowercase the first character of the replaced string. For example if $1 = TEST then \l$1 = tEST
- \U will convert to upercase all characters until next \E (or \L or if not present, to the end of the string)
- \L will convert to lowercase all characters until next \E (or \U or if not present, to the end of the string)
- \u\L will convert first character to upercase, then the rest of the string until \E to lowercase
- \l\U will convert first character to lowercase, then the rest of the string until \E to upercase
In order to help you make your choice, the results screen will display not only the translation as it is actually, with an highlight to the part which will be replaced, but also the full result of this replacement, that is, the same text with all replacements applied and highlighted in red. This can be useful especially in the case of regular expressions, to be sure that you will not accidentally add or remove more than expected:
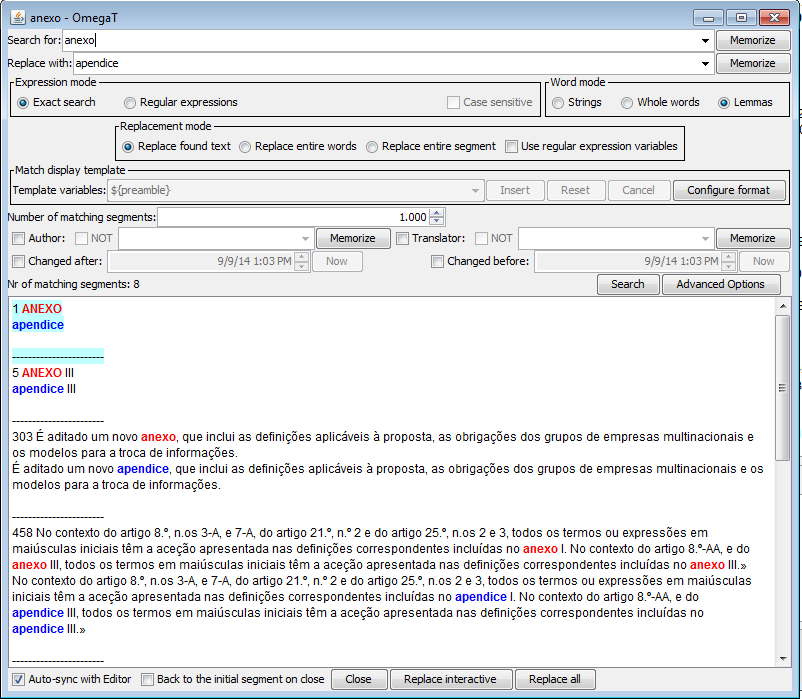
In any case, remember that this feature, if you do not like it, can be unactivated by selecting the correct matches display template.
For those who already use OmegaT, important notes:
First, you should note that our screen does not make search in orphan segments, as origial OmegaT did in version 3.6 (removed in 4.0). This could be changed (actually this is due to the fact that we use a different algorithm). But one point to consider is that when original screen found orphan segments, and you selected interactive search, these segments could not appear in the editor, so interactive search finally ignores them, even if they appeared during the search: don't you think that this can be a source of errors?
In OmegaT 3 and 4, the search & replace screen can be used for translated as well as for untranslated segments. In the second case, the «Search for» zone acts on the source, and a translation is added based on it.
In DGT-OmegaT, we consider this possibility as a totally distinct feature, named «Pre-translation», and we created a distinct screen for it. So, remember that replacements act only on already translated segments, and that the search is done in translated text, not in the source.
Add new comment