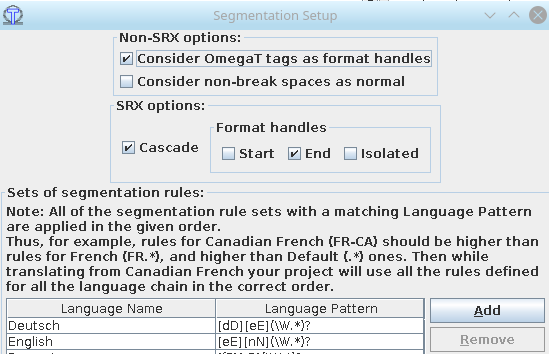
Segmentation improvements
Support for SRX format  [
[ ]
]
After discussion about RFE 1348, it appeared not clear to us why OmegaT uses two different formats for segmentation rules: the main rules, present in the JAR file, are in SRX format while the user-defined rules use an XML but OmegaT-specific format.
Then we found that there was already an old RFE asking whenever it would be possible to use SRX format instead of specific one. The two formats seem semantically equivalent, however we are not absolutely sure, that is the reason why we searched for a solution which also preserves compatibility and also easiness to convert between the two formats.
What is implemented in OmegaT 3.0 update 9 is the following rule:
- If segmentation.srx exists, use it;
- If segmentation.conf exists, use it (but SRX has priority);
- If segmentation-2srx.conf exists, on first load DGT-OmegaT will convert it to segmentation.srx, then continue;
- If segmentation-2conf.srx exists, on first load DGT-OmegaT will convert it to segmentation.conf, then continue;
The same rule is applied for the contents of common config directory as well as for project-specific segmentation. In any case SRX has priority over CONF format.
 In 2018 the core OmegaT team asked us for a port to OmegaT, but with different rules. The GitHub pull request was finally integrated in OmegaT 6.1 in 2023.
In 2018 the core OmegaT team asked us for a port to OmegaT, but with different rules. The GitHub pull request was finally integrated in OmegaT 6.1 in 2023.
 EXPERIMENTAL a limited, read-only support is implemented (in test/3.4 and dev/3.5 only) for Culter Segmentation Compatible Format (CSCX). This format enables to create template for redundant rules such as long lists of abreviations. The application will first check for segmentation.cscx, eventually with -2srx or -2conf for auto-conversion, exactly as done for SRX. This format is not a standard but it has a specification, also available in XML Schema, and it is easy to convert to SRX (the contrary would be more difficult): in the current implementation, if you use this format, change made via Segmentation Rules window will imply conversion to SRX, because this window looses CSC-specific features - the only case where OmegaT writes CSC is if you are using the popup menus. We already provide our specific segmentation rules in this format, but since this is experimental, it is not yet used by default.
EXPERIMENTAL a limited, read-only support is implemented (in test/3.4 and dev/3.5 only) for Culter Segmentation Compatible Format (CSCX). This format enables to create template for redundant rules such as long lists of abreviations. The application will first check for segmentation.cscx, eventually with -2srx or -2conf for auto-conversion, exactly as done for SRX. This format is not a standard but it has a specification, also available in XML Schema, and it is easy to convert to SRX (the contrary would be more difficult): in the current implementation, if you use this format, change made via Segmentation Rules window will imply conversion to SRX, because this window looses CSC-specific features - the only case where OmegaT writes CSC is if you are using the popup menus. We already provide our specific segmentation rules in this format, but since this is experimental, it is not yet used by default.
Again all of this should be seen as a proposal : feel free to comment these rules and propose alternative ones, if you want.
Support for format handles
In SRX header you have the possibility to define how to deal with formatting tags which would appear in a position of a split: you can chose whenever you want to have these tags in the segment before or after the split.
OmegaT did not take care of these values right now: it considered tags as part of the text. Usually the result is that when a tag appers in a position where there should be a split, the regular expressions do not match anymore and the split does not occur.
|
In new releases 3.4-TEST-4.0 and 3.5-DEV-5.0 (now in branches 3.6 and 3.7) we added the possibility to apply the following algorithm instead (example on the right):
Note that while all of this is based on SRX specification, strictly speaking, specification for point 3.2 does not clearly say what to do when there are multiple tags at break position. If you consider that algorithm part 3.2.1 or 3.2.2 is wrong, please let us know. |
Example. Let's say that we have following rule (very usual): <rule break="yes"> Phrase <t1/> ends.<i1/></e1><s1> <s2><i2/>Break fails. Logically a break should occur after the first dot, but since OmegaT considers the tags as part of the text, rule does not apply. Now with the new option activated, break will occur like this:
Once tags are removed (1), the rule aplies (2). Then when we re-inject tags (3), first isolated and ending tags are part of the segment before the break (3.2.1), while starting tag implies that all what is coming after is part of the after break segment (3.2.2). Tag <t1/> is not in a break, it remains in its initial location. |
|
|
The method is very similar to what we did here. Since it is experimental, and since it may break segmentation of old projects created before the option existed, it is preferable to keep it as an option. Normally, non-break spaces are not included in regular expression \s and for that reason, in most cases when your text contains non-break spaces, segments will not be splitted where they appear, which sounds logical. Unfortunately our users very often uses non-break spaces in location where they are not appropriate. The option "Consider non-break spaces as normal" enable to apply segmentation rules to them. We agree that this is not very logical, but as it is an option, use it or not, as you wish. Last nut not least, since format handles are now really meaningful for OmegaT, we add the possibility to configure them. Also the SRX cascade attribute, which works correctly in DGT-OmegaT (but not in standard OmegaT, which simply ignored it) is now configurable. |
Possibility to split/merge segments 


The idea comes from an old RFE from OmegaT sourceforge site: add contextual menus which "splits" a segment by, in reality, adding a new project-specific segmentation rule, and other ones to do the contrary:
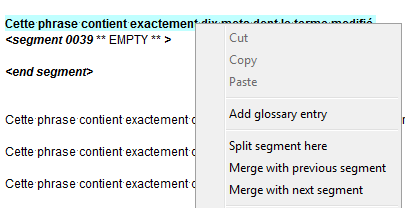 |
One important thing to consider is that the contextual menu appears when you select a position in the source of the active segment - in no case you split from the target. And you must check carefully where you split, because switching back is not easy - actually, we did not implement "merge" between segments which have been splitted manually, so you have to go to segmentation rules editor! We restricted it to active segment for technical reasons, it may change in the future. |
In releases 3.4-TEST-4.1 and 3.5-DEV-5.1 (now 3.6 and 3.7 only), if you are using CSC format, new menus enable to add abbreviations or ordinal followers. These menus are generated based on the templates defined in the CSC file itself, reason why it is not available for SRX files yet.
Split
| To avoid errorful use of this feature, when you click on the menu the build of the rule is not immediate; instead, you can modify it and confirm or cancel: | 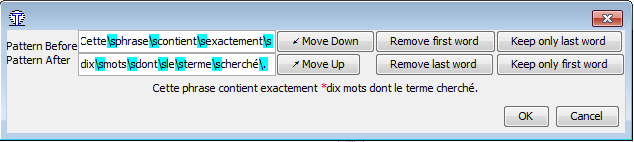 |
In this window, buttons help you to make corrections in the two edition zones (you can edit the text yourself, if you prefer):
- Move Up and Move Down are useful if you did not select the correct point in the segment: they will take exactly one character from one zone and move it to the other one, which gives the same effect as if you had selected one character before or after. If the captured character is an escaped one (with backslash, in blue) the backslash will be captured as well.
- Remove and Keep only buttons are useful if you do not want to use the full phrase to define the rule (in most cases you probably want to keep only a small part of the segment but this cannot be anticipated)
After the two edition zones, you can see the portion of the segment you are editing, with an asterisk in red showing where exactly you are cutting. When you use the previous buttons, this text changes so that you can immediately see the effect.
This method seems not to work when there are tags in the segment (the segmenter does not recognize < or > correctly). To avoid that, the rule which is built when you use the split menu uses the contents of the segment until a tag: a segment such as "This is <t1/> a test" splitted just after the first word will generate a rule with after = " is " (it stops after the space but before the tag). And if you try to split inside or in the bounds of a tag, an error message tells you that this is not possible.
Merge
The contrary operation, named merge, is potentially more source of errors. The reason is that it only works if the two segments to merge are in the same paragraph in the source file. But the problem is that OmegaT shows nowhere if it is the case or not. So finally we had to add two things:
- Memorize in source entry whenever it starts a paragraph or not; do not generate "merge" contextual menu if it is impossible (in the beginning of a paragraph you can only merge with next segment; in the end, you can only merge with previous)
- Add a view menu to display paragraph delimiters - this is what is discussed in next section.
Display paragraph delimiters 
A new menu enables to see delimiters between paragraphs, so that you can see whenever you can merge or not:
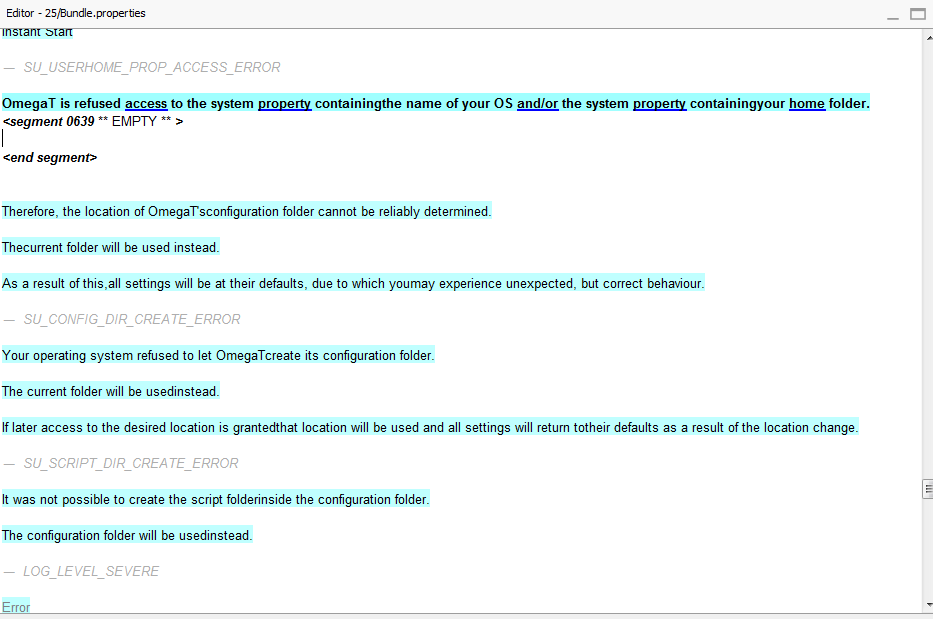
Line breaks appear between segments which are in the same paragraph. Line in gray appear between paragraphs.
[Addition] This feature had from a long time been requested for OmegaT (RFE 314 or RFE 431), and our code was finally integrated in OmegaT 4.1.5 update 4. However, there is a small difference: we also added the possibilty to use variables in the template - for the moment, only the key elements such as entry id or path (note: all source text entries from same paragraph share the same key). This is useful for file formats like Java Properties, where the key gives some information about where the text will appear in localized application. The screenshot above comes from DGT-OmegaT where we open the properties file from OmegaT itself.
Be careful that contrarily to what was recently implemented in OmegaT 4.1.4, if you want more than one line between the marker and the first segment, you must ask it explicitly by putting "\n" in the pattern (because some people may prefer to have no blank line between marker and segment). In the future we may also add as a variable the paragraph type (for example <h1> or <p> in html documents) but since it requires significant changes in the filters architecture, we are not sure it is really possible.
Comments
Michael Beijer (not verified)
Fri, 01/03/2019 - 11:56
Permalink
new design of paragraph markers
I really love the new look of the paragraph markers Very nice!
admin
Fri, 01/03/2019 - 15:53
Permalink
Re: new design of paragraph markers -- Configurable
Hi Michael
Thanks for your comment.
Good news, part of this work is now integrated in future OmegaT 4.1.5 update 4 (not yet published, only in the SVN)
However even if they took part of my code, there are still some differences: what do you think about configuration with variables?
Add new comment