Search and Pre-translate
An important thing in "Search and replace" screen is that the zone «Search for» is always related to the content of translated text: this screen is mainly used to correct errors. Not only it does nothing on untranslated segments, but it will always base its work on the current translation, not the source. What does the original OmegaT in this case is, in our mind, a totally distinct feature which we call pre-translation and which is the topic of this article.
Sometimes you have a lot of segments whose translation is trivial: for example, segments containing only numbers, due to a bad segmentation rule, should be translated identical to the source. The Pre-translate screen is made for such purposes :
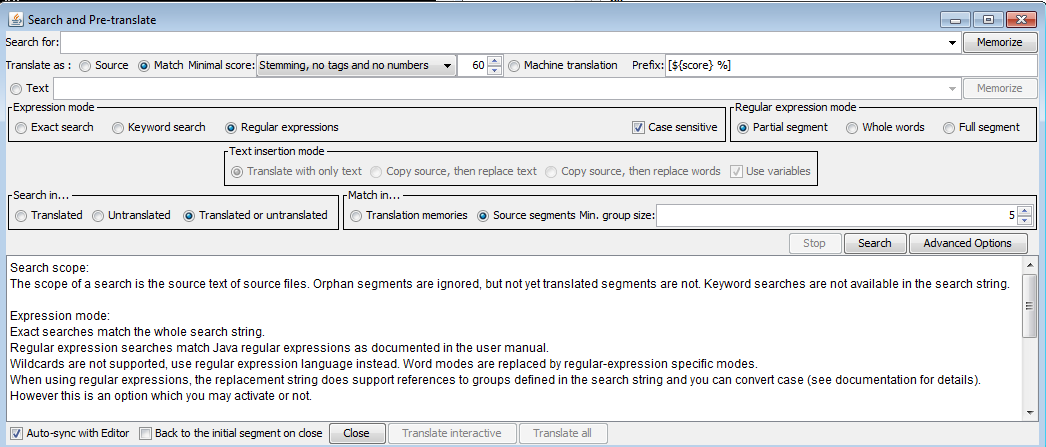
Here the «Search for» zone relates to the source segments, not the target segments. And be careful about the «Search in» zone, in particular if you don't want to reparse already translated segments!
Now the only specific feature of this screen is that you have to decide what you want to use for the translation, once a segment is found. Possibilities include:
-
Source: the segment is translated identically to the source
 New in DGT-OmegaT 3.2 update 9: when "Translate as Source" is selected, the Text insertion mode (5th line) has new options:
New in DGT-OmegaT 3.2 update 9: when "Translate as Source" is selected, the Text insertion mode (5th line) has new options: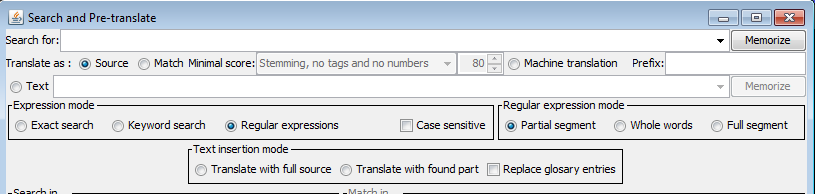
-
Translate with full source: create a translation identical to the source
-
Translate with found part: create a translation identical to which was found by the search
For example,if you searched for regular expression \d+ and source contains "25 documents", then "Translate with full source" will translate by "25 documents" while "Translate with found part" will translate with only "25", the result of the regular expression. -
Replace glossary entries: does the same as what the option in "Options => Glossaries" menu would have done inside the editor.
Initially the idea was to re-use exactly the same algorithm. But some people complained that it did not work for multi-word entries. It is true with OmegaT 3.6's algorithm - this has been corrected in 4.1, but in a way not usable here. So, finally in DGT-OT 3.2 update 10, we re-use here the algorithm used for transtips, which detects in preference longer terms. And the modification will also affect replacement in the editor.
Note: when you use this option, glossaries are explored using the same options as in "Gloassary Pane and Transtips configuration". The fact that it takes care of lemmatization or not depends on the just mentioned window, not from Expression+Word mode, which are only here for the "Search for" field!
-
-
Match: uses the «fuzzy search » (note: from the entire project, including tmx files and already translated segments!) and inserts the best result found. If no result has a score better than the Match Minimal score, the segment is simply not included in the list of changes. Here you can select the minimal score and which score criteria is used.
-
Machine translation. If more than one MT engine is installed (so, if the MT_plugins.jar is present) you can select which engine to use, else the engine selector disappears.
Note: the 3 last options (source with glossaries, matches and machine translation) are known to be time-consuming. Previous releases gave the impression that the application is totally freezed during the search. To avoid this we first implemented features for long queries. Later, realizing that this can affect also the "Translate all" button, we changed the algorithm to re-use result of the search. If you have the impression that the application freezes, please download version 3.2 update 14 or later. -
Text: here you can set a free text for the replacement. Then a new zone called "Text insertion mode" gives you the possibility to decide what to do with this text (this zone is a reflect of Search&Replace's "Replace mode", but it is only active if you select "Text" as translation):
Finally this zone also enables you to use regular expression variables, exactly as in Search&Replace screen, except that the variables are filled using a search in the source, not in the target.
-
Translate with only text: create a translation which contains only what you typed in the "Text" zone;
-
Copy source, then replace text: create a translation identical to the source except that the part of the segment which has been found is replaced by the given text;
-
Copy source, then replace words: identical, except that if the found part is in the middle of wods, the entire word is replaced
-
In all cases, a prefix can be added before all translations, exactly as standard OmegaT does during automatic insertion of matches in the editor, but we added a special feature: the prefix can make reference to the score variables, in which case it will differ for each segment:
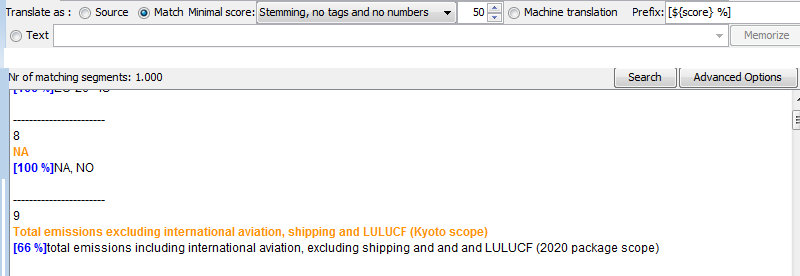
This feature (using variables in the prefix) is also added in the editor insertion.
Pseudo-translation in command line
OmegaT has a command-line mode which enables to create a project tmx file based on the source files of a project. Actually, the generated file can contain either empty translations or translations identical to the source.
DGT-OmegaT enlarges the concept with the same features as for pre-translation : you can pseudo-translate a file based on machine translator: simply replace pseudotranslatetype parameter with the name of the machine translation (class name without "MachineTranslate").
match non-translated source segments
Until now, option "Translate as -> matches" worked exactly as the matches pane and statistics: each segment found during the search phase was matched against translation memories segments, including those from the project memory but excluding non-translated segments, because they are not in the project memory at all.
After DGT-OmegaT 3.0 update 24, a new pane named "Match in", which is available only when "Translate as = matches", enables to search in translation memories, as before, or, alternatively, to match against all source segments, whenever they are translated or not.
When it is used, contrarily to previous searches, segments are not associated to a translation, but grouped by similarity: when two segments of the source document have a match more than selected percentage, they are put in a group, then the window displays all found groups:
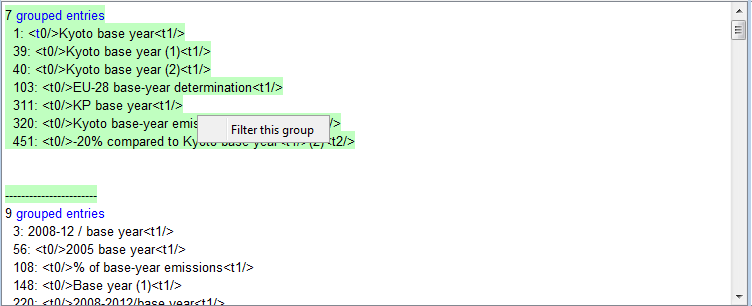
This enables to check for similarities inside a document before translation: sometimes translator prefers to work in a non-linear mode (especially when you translate software, where order is not so strict as in documents).
When you use this mode, buttons "Translate all" and "Translate interactive" are not available, since the search did not choose any translation, but simply did groups. Instead, you can use a popup menu: if you click to one of the groups, a popup menu "Filter this group" will add a search filter on the editor (not a replace filter, but the same as in "Search" screen!) where only segments from this group are kept. You can now translate this group, then either remove the filter or go back to the pre-translate window and filter another group.
Add new comment